Skip to content
Menu
OPENXTRA | Server Room Monitoring
Blog
Environment Monitors
Sensors
About Us
Contact Us
Support
Close Menu
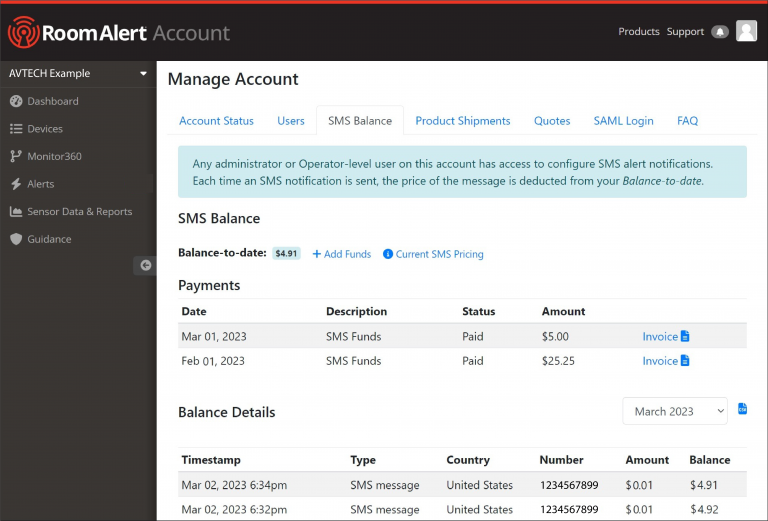
Native SMS Alert Notifications in Room Alert Account
September 6, 2023
Read More
Improve Your Sustainability Strategy With The Digital Active Power w/Temperature Sensor
August 25, 2023
Read More
Reduce Heating & Cooling Costs with Room Alert Environment Monitoring
August 25, 2023
Read More
Strengthen Your Business Insurance Plan With Room Alert
August 25, 2023
Read More
Protect Cold Storage In Schools With Room Alert
August 25, 2023
Read More
Room Alert 3 Wi-Fi End-Of-Life Announcement
August 25, 2023
Read More
ANNOUNCEMENT: OPENXTRA Acquired By AVTECH Software, Inc.
August 25, 2023
Read More
Reduce Operational Costs & Prevent HVAC Downtime With The Digital Temperature & Air Flow Sensor
August 25, 2023
Read More